Every time you load a webpage, stream a video, or send a message, countless invisible decisions are made in milliseconds: which path should this data take? Routing algorithms are the mathematical procedures that answer that question and the elegance of their design quietly underpins the entire modern internet.
A data packet departing its source node faces a sprawling maze of interconnected routers. There is rarely a single route from A to B; instead, there are dozens perhaps hundreds of possible paths, each with its own cost in terms of distance, congestion, or transit time. The job of a routing algorithm is to compute the least-cost path through that maze and do so fast enough that the network remains useful.
“A routing algorithm doesn’t just find a path it finds the best path, under conditions that may be changing every second.”
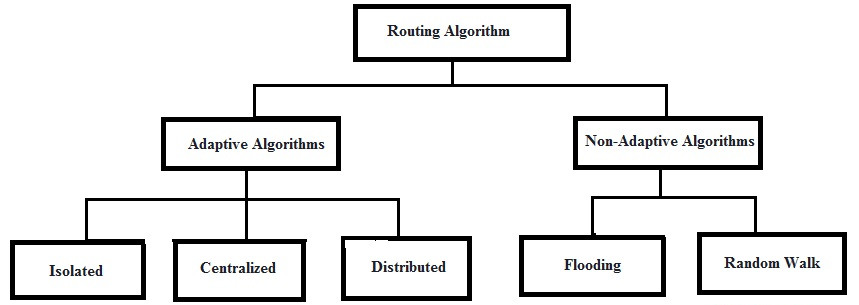
At the highest level, routing algorithms divide into two broad families: adaptive algorithms, which respond to the network’s live conditions, and non-adaptive algorithms, which rely on a fixed map decided at startup. Understanding the difference between them is the first step to understanding how routers actually think.
Adaptive Routing Algorithms
Adaptive routing algorithms also called dynamic routing algorithms are the more sophisticated family. They continuously monitor the state of the network: congestion levels, link failures, changing topologies. When conditions shift, they update their routing tables accordingly, always seeking the current optimal path. The three principal varieties differ in where the intelligence lives.
Centralized Algorithm
Adaptive The centralized algorithm operates with complete, global knowledge of the network. A single node or a dedicated controller collects information about every link and every router, then computes least-cost paths for the entire network from that privileged vantage point. Because it relies on a comprehensive picture of the topology, it is also known as a global routing algorithm.
The power of this approach is precision: with full information, the computed path is genuinely optimal. The tradeoff is fragility and scalability. A single controlling node becomes a bottleneck and a point of failure. On large networks, the volume of state information becomes prohibitive.
Isolated Algorithm
Adaptive Rather than gathering information from its neighbors, the isolated algorithm makes routing decisions using only local information data visible to the individual router itself. No network-wide state is collected or exchanged. Each router acts independently, drawing on its own experience of traffic patterns and link conditions.
This self-reliance makes isolated algorithms robust and lightweight, but their decisions can be suboptimal. A router acting on incomplete information may choose a path that looks locally efficient but is globally poor sending a packet down a corridor that leads to a bottleneck it cannot see.
Distributed Algorithm
Adaptive The distributed algorithm strikes the middle ground. Rather than centralizing intelligence or isolating it, it spreads computation across all routers in the network. Each node begins with knowledge of only its immediate neighbors; over successive iterations, routers exchange information and progressively converge on the globally optimal least-cost paths.
This iterative, decentralized design is the basis of widely deployed protocols such as RIP (Routing Information Protocol) and OSPF (Open Shortest Path First). It scales gracefully and tolerates individual node failures if a router goes down, the remaining nodes simply re-converge around it.
Non-Adaptive Routing Algorithms
Where adaptive algorithms treat the network as a living system to be continuously re-read, non-adaptive algorithms also called static routing algorithms treat it as a fixed map. Routing tables are computed once, when the network boots, and remain unchanged during operation. This simplicity is both their virtue and their limitation: fast and predictable, but blind to change.
Flooding
Non-Adaptive Flooding is the most straightforward routing strategy conceivable: when a packet arrives at a router, it is immediately forwarded out through every outgoing link except the one it arrived on. The packet fans out through the entire network, guaranteed to reach its destination by every possible route.
Flooding can be uncontrolled (packets replicate indefinitely until a hop count expires), controlled (a sequence number prevents the same packet from being forwarded twice), or selective (only the most promising links are flooded). The approach guarantees delivery and requires no routing table whatsoever but at the cost of enormous bandwidth consumption. Flooding is not generally used for ordinary traffic; it finds application in network discovery, broadcast scenarios, and resilience testing.
Random Walk
Non-Adaptive Random walk is a probabilistic algorithm in which each router, upon receiving a packet, forwards it to one randomly chosen neighbor. There is no route computation, no topology table, no strategy only chance. The packet wanders the network until it either reaches its destination or expires.
Like flooding, random walk requires no routing state and is trivial to implement. Unlike flooding, it generates minimal traffic. In practice, random walk is rarely used in production networks; it appears primarily in theoretical analysis, in certain peer-to-peer systems, and as a baseline against which more sophisticated algorithms are measured.
A Side-by-Side Comparison
| Algorithm | Type | Knowledge used | Adapts to change? | Overhead |
|---|---|---|---|---|
| Centralized | Adaptive | Global (full topology) | Yes | High (state collection) |
| Isolated | Adaptive | Local only | Yes | Very low |
| Distributed | Adaptive | Neighbor-shared, iterative | Yes | Moderate |
| Flooding | Non-Adaptive | None required | No | Very high (bandwidth) |
| Random Walk | Non-Adaptive | None required | No | Very low |